为什么角色文档、记忆系统和系统提示永远无法让AI活过来 — 以及什么能。
三个问题
如果想让AI有灵魂,只给它一个 soul.md 够吗?
如果想让AI聊天时有”人味”,只加强 memory 就可以了吗?
如果真想要一个能跟自己长久聊天的AI伴侣,光给它一堆角色设定文档就够了吗?
三个问题,答案全是否定的。
当今所有热门的AI角色扮演项目 — 从 SillyTavern 到 Character.AI,再到围绕 OpenAI 和 Claude 构建的各种项目 — 都遵循同一个基本模式:写一份详细的角色描述,粘贴到系统提示词里,然后期望语言模型完成剩余的工作。有些加了记忆,有些加了世界书,有些加了精心设计的多轮提示策略。但架构完全一样:LLM通过阅读人格描述来”假装”拥有人格。
2025年,角色扮演聊天在AI领域的token消耗位居第二。数百万用户在为与AI角色对话付费。我认为各位用户值得拥有真正有灵魂的AI伴侣 — 而不是穿着人格外衣的角色。
本文记录了我的一次探索,试图证明这样一个论点:AI的灵魂不是Prompt写出来的。它是随着时间、事件和记忆,在底层心理学公式的计算和演进中生长出来的。
提示词的幻觉
看看当你给LLM一份角色文档时会发生什么:
名字:格雷戈尔
性格:焦虑、充满负罪感、对家庭无比忠诚
背景:一天早上醒来发现自己变成了一只虫...
价值观:家庭责任高于一切LLM阅读了这些,然后生成听起来焦虑、愧疚、忠诚的文本。一轮又一轮,它产出与这些特质一致的回复。用户觉得自己在跟一个角色对话。
但问一个更深的问题:50轮对话之后,这个角色变了吗?
在玩家持续表达善意之后,格雷戈尔的负罪感减轻了吗?在一个被接纳的时刻之后,他的焦虑降低了吗?在发现家人的怨恨之后,他的忠诚动摇了吗?
在所有基于提示词的系统中,答案是没有。第50轮的格雷戈尔和第1轮的格雷戈尔完全一样。系统提示写着”充满负罪感”,所以LLM就一直生成充满负罪感的文本。如果你希望角色发生变化,你 — 用户或开发者 — 必须手动重写提示词。
这就是根本性的幻觉:LLM生成的是关于人格的文本,而不是在计算人格。
记忆系统不能解决这个问题。记忆库存储了发生过什么 — “玩家在第12轮说了一句善意的话” — 但它不处理这段经历对角色心理状态的意义。LLM可能会引用这段记忆并生成看似受其影响的回复,但底层并不存在”善意如何转化负罪感”或”持续的善意最终如何消解焦虑”的模型。LLM在即兴发挥,不是在计算。
世界书也不能解决这个问题。世界书告诉LLM关于世界的事实,但不告诉LLM角色与这些事实之间的关系如何随经历演变。
差距不在提示词的质量上,而在架构上。无论多么精妙的提示词工程都无法产生真正的人格演化,因为提示词工程作用于描述,而非模型。
人格作为动力系统
人类的人格不是静态的。一个20岁时轻易信任他人的人,到40岁可能变得警觉 — 不是因为有人重写了他的角色卡,而是因为累积的经历重塑了他的信念结构。一次毁灭性的背叛可以在瞬间摧毁多年积累的信任。而重建信任的路,比失去信任的路更长更难。
这不是叙事上的便利。这是心理系统的特性:信念在经历中形成,根据自身的极端程度抵抗变化,在矛盾中累积压力,偶尔经历灾难性的重组。
NSP-roleplay 提出的问题是:我们能计算这些吗?
不是近似。不是让LLM”表演一个信任正在下降的角色”。而是用方程、状态向量和确定性更新规则来计算 — 让人格演化作为累积经历的输出自然产生。
信念网络:数学基础
在 NSP-roleplay 中,每个角色都有一个信念网络 — 一组介于0.0到1.0之间的连续数值,每个代表一个心理维度:
people_are_trustworthy: 0.7 // 人是否值得信赖
self_worth: 0.5 // 自我价值感
duty_above_desire: 0.8 // 责任高于欲望
vulnerability_is_weakness: 0.3 // 脆弱是否等于软弱这些不是标签,是状态变量。它们基于对话中发生的事情,每轮都在变化。
关键机制是精度(precision) — 信念抵抗变化的程度:
precision = extremity * (1 - accumulated_load) * (1 - emotion * 0.3)
其中:
extremity = |belief_value - 0.5| * 2.0 // 距离中性点的距离
accumulated_load = 不可逆累积压力 // 范围 [0, 1]
emotion = 当前情绪强度 // 范围 [0, 1]这产生了一个关键特性:极端的信念是刚性的,温和的信念是流动的。 深度信任(0.9)或深度不信任(0.1)的角色很难被改变。处于中间位置(0.5)的角色容易转变。
但还有第二个特性,正是它让角色感觉活了起来:累积负荷会侵蚀精度。 一个持续承受压力、遭遇矛盾、被逼到极限的角色,更容易发生改变,无论他们的信念原本多么极端。心理韧性有上限。这也是电影《小丑》的叙事逻辑。
第三个特性:强烈的情绪会暂时降低精度。 在极度恐惧或愤怒的时刻,即使刚性的信念也会短暂变得可塑。这就是为什么角色在危机中做出平时永远不会做的决定 — 然后不得不承受后果。
灾变:角色如何崩塌
微小的经历产生微更新:
belief += weighted_error * 0.05 // 学习率:每轮几乎不可感知一次善意的举动不会明显改变格雷戈尔的信任度。它偏移了0.02。看不见。但它在累积。
同时,经历与信念之间的矛盾产生应变(strain) — 可恢复的心理压力:
strain = |weighted_error| + strain * 0.95 // 指数衰减应变会消退。糟糕的一天会被遗忘。但当应变超过阈值时,超出的部分转移为负荷(load) — 不可逆的心理损伤:
if strain > 0.3:
load += (strain - 0.3) * 0.1 // 永久累积负荷不会衰减。负荷不会随时间消退。负荷是反复心理压力留下的疤痕组织。
当负荷超过灾变阈值时:
if load > 0.5:
belief = 0.3 if belief > 0.5 else 0.7 // 跳跃至中线对侧
load = 0.0 // 转化为新的人格
record_milestone(turn) // 记录里程碑信念不是逐渐漂移,而是断裂式跳跃到对立面。一个信任他人的角色(0.8)不会慢慢变得谨慎 — 他们灾变性地崩溃到不信任(0.3)。一个拒绝脆弱的角色(0.2)不会温和地敞开心扉 — 他们在一个转变性的瞬间突破到开放(0.7)。
这是尖点灾变理论在人格建模中的应用。同样的数学描述了桥梁如何在逐渐增加的载荷下突然断裂,或者公众舆论如何在多年缓慢积压后一夜翻转。
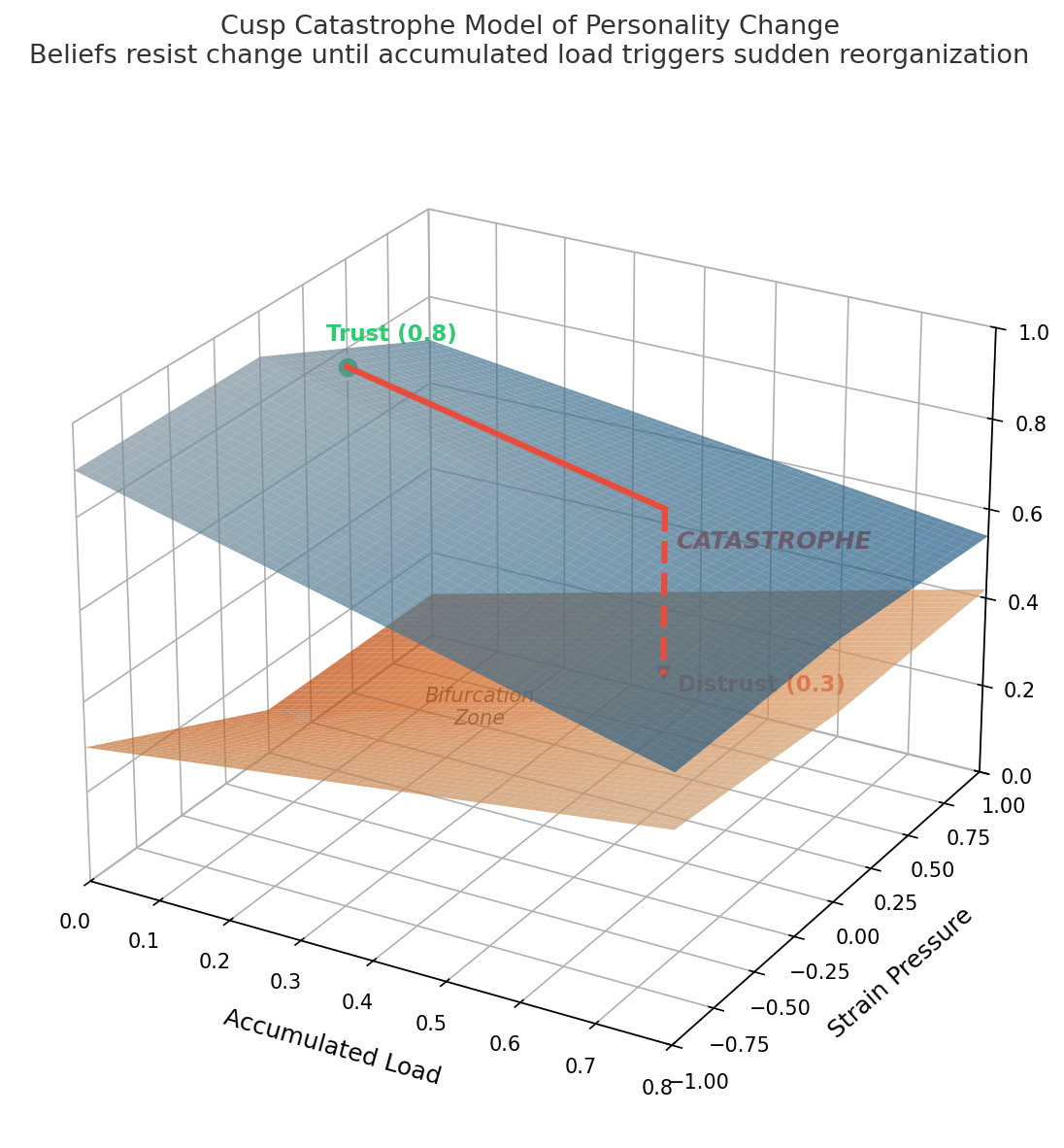 这里有一个不对称性,让它感觉真实:从信任到不信任的路径,与从不信任回到信任的路径,不是同一条路。 灾变之后,角色落在0.3 — 一个极端位置,精度很高。要回到0.7,需要累积足够的新负荷来触发又一次灾变。花了30轮累积背叛才完成的崩塌,可能需要60轮持续的善意才能逆转。角色在它们的精度函数中携带着自己的历史。
这里有一个不对称性,让它感觉真实:从信任到不信任的路径,与从不信任回到信任的路径,不是同一条路。 灾变之后,角色落在0.3 — 一个极端位置,精度很高。要回到0.7,需要累积足够的新负荷来触发又一次灾变。花了30轮累积背叛才完成的崩塌,可能需要60轮持续的善意才能逆转。角色在它们的精度函数中携带着自己的历史。
先感受,再思考:事件评估
同一事件对不同角色的影响不同。
当谎言被揭穿时,自我价值感高(0.8)的角色体验到的是愤怒 — 可控性维度主导(”我能对此做点什么”)。自我价值感低(0.2)的角色体验到的是羞耻 — 合意性维度主导(”这证实了我对自己的怀疑”)。
这是OCC评估模型:每个事件通过四个维度被评估:
| 维度 | 问题 | 范围 |
|---|---|---|
| 相关性 (Relevance) | 这件事对我重要吗? | [0, 1] |
| 合意性 (Desirability) | 这对我的目标是好是坏? | [-1, 1] |
| 可控性 (Controllability) | 我能影响这件事吗? | [0, 1] |
| 新奇性 (Novelty) | 这有多出乎意料? | [0, 1] |
评估结果输入到双通道行为引导:
冷通道(理性):我的信念、承诺和义务说我应该做什么?
热通道(情感):我的直觉、当前情绪和躯体标记推动我做什么?
两个通道通过 sigmoid 函数混合:
mix_weight = 0.2 + 0.6 * sigmoid(emotion_intensity)
// 情绪 = 0.0 --> mix = 0.2 (80% 理性, 20% 情感)
// 情绪 = 0.5 --> mix = 0.5 (平衡)
// 情绪 = 1.0 --> mix = 0.8 (20% 理性, 80% 情感)平静的角色基于信念和承诺做决定。情绪崩溃的角色凭直觉行动。这不是叙事选择 — 它由当前情绪状态计算得出,而情绪状态本身由事件评估计算得出,事件评估又由角色的信念网络计算得出。
LLM收到的是自然语言形式的引导:“这个角色非常重视责任(理性),但目前对[某实体]充满愤怒(情感)。当前状态倾向35%理性、65%情感。” LLM产出与此状态一致的对话 — 但它没有计算这个状态。状态是为它计算好的。
角色知道什么(以及不知道什么)
大多数角色扮演系统将知识视为二元的:角色知道某件事,或者不知道。NSP-roleplay 建模了一个8态认知谱系:
| 状态 | 含义 | 行为影响 |
|---|---|---|
aware |
正确知晓 | 基于准确信息行动 |
misbelieves |
自以为知道,但错误 | 戏剧反讽的来源 |
suspects |
有猜测,不确定 | 谨慎、试探性行为 |
partially_aware |
只知道部分真相 | 基于不完整画面行动 |
unaware |
不知道 | 无法基于此行动 |
forgot |
曾经知道,已遗忘 | 可以被提醒 |
overwhelmed |
知道但无法处理 | 逃避、瘫痪 |
denies |
知道但拒绝接受 | 防御性矛盾 |
思考 unaware 和 denies 之间的区别。一个对真相”不知情”的角色只是不会提及它。一个”否认”真相的角色会主动反驳证据、在被追问时变得防御、展现出心理否认的特定行为模式。
这些状态通过经历发生转换:unaware –> suspects –> denies –> aware。每次转换由对话中的具体事件触发,并记录发生的轮次。角色的知识不只是改变 — 它经历着心理学上连贯的阶段性演化。
像人一样记忆
人类的记忆不是数据库。我们不按时间戳检索事件。我们按情感显著性、人格影响和当前相关性来检索。
NSP-roleplay 的记忆召回优先级函数反映了这一点:
priority = (
time_decay(age, emotional_intensity) * 0.2 + // 时效性权重最低
personality_impact * 0.3 + // 人格影响权重最高
emotional_intensity * 0.2 +
keyword_relevance(memory, current_context) * 0.3
)来自第5轮的创伤性背叛有 personality_impact: 0.8 和 emotional_intensity: 0.9。到第100轮时,它的召回优先级仍然很高 — 角色不断回想它、引用它、被它影响。而第90轮一次愉快但平淡的对话,早已褪去。
这就是闪光灯记忆效应:高情感事件抵抗正常的遗忘曲线。角色不会”平等地记住一切”。他们记住的是伤害他们的事、改变他们的事、以及此刻相关的事。
睡眠:魔法发生的地方
LLM的上下文窗口是有限的。每个角色扮演系统终将撞上这堵墙。通常的解决方案是无声地截断或总结 — 对话悄悄失去最早的几轮。
NSP-roleplay 将这个限制变成了一个叙事机制。当上下文使用超过60%时,角色会以角色内的方式建议休息:
“我有点累了…可以休息一会儿吗?”
在睡眠期间,系统运行一个批处理管线:
- 应变恢复:
strain *= 0.95^8(约33%的降低)。负荷不恢复。 - 情绪衰减:强度减半。低于0.1则重置为中性。
- 记忆整合:相关记忆按关键词重叠度聚类,合并为整合条目。
- 人格存档:完整状态快照保存(为分支/平行剧本提供分叉点)。
- 观察者分析:对累积的状态历史进行弧线检测。
当角色”醒来”时,上下文窗口是新的,但人格状态是连续的。没有信息丢失 — 它已被处理进角色的心理状态中,归属于那里。
玩家不会感受到上下文管理。他们感受到的是一个有时需要休息的角色,醒来后感觉好了一些(应变降低,情绪更平静),偶尔对近期事件有了新的理解(观察者分析)。工程限制变成了角色特质。
涌现弧线:没有人编程的模式
传统叙事系统预先定义角色弧线:”这个角色将从不信任走向信任。”系统然后强制执行这个轨迹。
NSP-roleplay 反转了这一点。观察者层分析人格状态历史,在弧线涌现之后才识别模式:
if max_single_step >= 0.2: arc = SUDDEN_JUMP // 突变
elif direction_changes >= 3: arc = OSCILLATION // 摆荡
elif |total_delta| > 0.1: arc = GRADUAL_SHIFT // 渐变
else: arc = PLATEAU // 稳态一个在40轮中从不信任(0.3)缓慢移动到信任(0.6)的角色被分类为 GRADUAL_SHIFT。一个信任值在多次灾变中在0.3和0.7之间震荡的角色被分类为 OSCILLATION — 内心冲突通过数学变得可见。
观察者永远不会反馈到生成中。它不会告诉LLM”这个角色正在经历一条弧线”。它观察数学已经产生的结果。这防止了困扰那些让叙事标签影响行为的系统的反馈循环 — 一个被标记为”救赎弧线”的角色不会因为标签而开始表现出救赎行为。他们的行为完全由数学决定,观察者只是描述发生了什么。
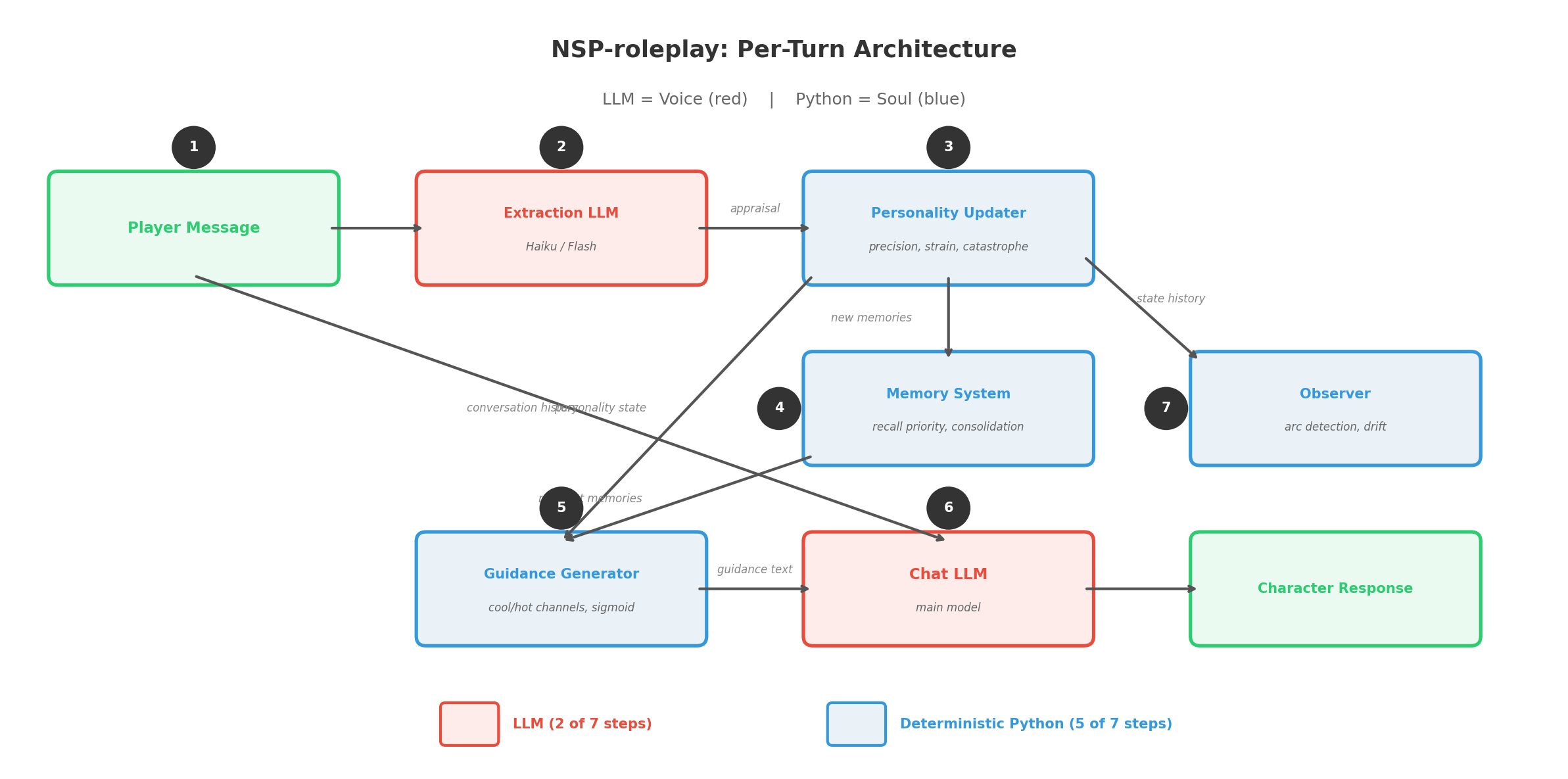
架构:LLM是声音,不是灵魂
以下是 NSP-roleplay 每一轮实际运行的内容:
- 玩家发送消息 –> 对话历史
- 抽取LLM(廉价、快速 — Haiku/Flash级别)解析对话,输出结构化评估:相关性、合意性、情绪反应、受影响的信念、新记忆、认知更新
- 人格更新器(确定性Python)计算:每个信念的预测误差、每个信念的精度、应变/负荷累积、灾变检查、新情绪状态
- 记忆系统(确定性Python)存储新记忆及其召回优先级,检索上下文相关的记忆用于注入
- 引导生成器(确定性Python)将当前人格状态渲染为冷/热通道文本,附带混合权重
- 聊天LLM(主模型)接收:引导文本 + 相关记忆 + 认知状态 + 对话历史 –> 生成角色回复
- 观察者(确定性Python,周期性)分析状态轨迹,检测弧线,识别漂移
LLM恰好出现在两个位置:第2步(抽取)和第6步(回复生成)。其他一切 — 每次信念更新、每次灾变、每次记忆优先级排序、每次弧线检测 — 都在LLM之外用确定性代码计算,有1182个单元测试覆盖。
LLM是声音。Python是灵魂。
这证明了什么
拿同一张角色卡 — 格雷戈尔·萨姆萨,带着他的负罪感、忠诚和焦虑 — 跑两段不同的对话。一段中玩家持续友善,另一段中玩家态度敌意。
在基于提示词的系统中,两段对话产出的格雷戈尔大致相同。系统提示写着”焦虑且充满负罪感”,LLM就生成焦虑、充满负罪感的文本,不管上下文如何。
在 NSP-roleplay 中,两个格雷戈尔分化了。善意版格雷戈尔的自我价值缓慢上升(每轮微更新+0.02)。他的焦虑应变累积但会衰减。30轮后,他的自我价值信念从0.3漂移到0.5。他有了可测量的不同 — LLM的回复反映了这一点,因为它收到的引导已经改变了。
敌意版格雷戈尔的自我价值应变累积速度超过衰减速度。负荷在积累。到第25轮,负荷越过灾变阈值。他的自我价值不是逐渐下滑 — 它从0.3跳变到0.7。他不再自我贬低,变得坚定,甚至带有反抗。观察者检测到一条 SUDDEN_JUMP 弧线。一个里程碑被记录。这不是编程出来的。不是剧本写的。它从累积压力遇上灾变阈值的数学中涌现了出来。
这就是AI角色”拥有灵魂”的含义。一段描述人格的提示词根本不足以赋予灵魂,灵魂需要一个人格栖居其中的计算基底 — 对经历做出反应,累积历史,抵抗改变直到再也不能,然后偶尔以连设计者都意想不到的方式发生转变。没有时间轴,没有计算基底的灵魂只是假装的又一层壳。
灵魂从来不由一段提示词决定,它是一个携带时间轴的过程。
v9:信念不是孤岛
上述描述的是基础引擎。在经历了多轮展示测试之后,几个边界条件暴露了引擎的局限性。v9版本引入了5项优化,每一项都让系统更接近真实的心理动力学:
维度共振矩阵。 真实的人类心理中,信念不是独立运作的。对家庭的失望会侵蚀对社会的信任。自尊的崩溃会削弱职业自信。v9通过network_links建模了这种耦合:当一个信念维度的应变值极高时,与它关联的维度的精度会被降低 — 抵抗变化的能力被跨维度传导的压力侵蚀。
resonance_factor = 1.0 - resonance_strength * overflow
// 关联维度的应力越高,本维度的精度越低
// precision *= resonance_factor渐进式突变。 基础引擎的突变是二值跳跃 — 0.3或0.7。但真实的心理崩溃有强度之分。一次轻微的裂痕和一次毁灭性的崩塌不应该跳到相同的位置。v9让跳跃距离与累积负荷成正比:
distance = 0.05 + 0.30 * load
attractor = 0.5 - distance // 或 0.5 + distance
// load=0.5(阈值):distance=0.20,温和的转变
// load=1.0(极限):distance=0.35,剧烈的崩塌正面事件恢复。 基础引擎中,负荷只增不减。这在数学上是准确的(心理伤疤不会消失),但在叙事上过于悲观。v9允许正面事件(desirability > 0)轻微减少负荷 — 不是治愈伤疤,而是让角色在好的经历中获得微小的喘息空间。
应力持续加速。 连续多轮处于高应力状态会让负荷转移加速。第一轮高压产生基础负荷转移;第五轮连续高压产生5倍于基础的转移速率。持续的折磨比间歇性压力更具破坏性 — 这与创伤心理学的研究一致。
情绪矛盾标记。 当主情绪和副情绪的效价相反时(例如,主:愤怒/负面,副:感激/正面),系统标记ambivalence,引导LLM表现出内在矛盾而非简单的情绪表达。
实战证据:测试揭示了什么
理论需要实证。以下是两个展示测试的关键发现。
曹操:情感控制的崩溃与重建
角色:60岁的曹操,丞相,诗人,暴君。9轮对话中,一位医师逐步揭露他的心理创伤。
- 情感控制从0.90崩溃到0.012,然后重建到0.70。 不是恢复到原始值。0.70代表一种新形态的控制 — 基于接受而非压抑。系统将情感宣泄识别为控制的重建,而非崩溃的延续。
- 潜意识负罪感从0.25持续下降到0.087。 表面上反直觉 — 忏悔应该增加负罪感。但系统追踪的是潜意识负罪感:当曹操公开承认罪行时,负罪感从潜意识”毕业”到了意识层面。数值下降不意味着更少的内疚,而是更少的潜意识内疚。
- 才德观(meritocracy)锚定在0.80不变。 整个心理崩溃过程中,对才华的欣赏从未被触碰。这解释了为什么曹操不杀医师 — 不是因为论证有说服力,而是因为信念网络中”此人有才”的评估从未动摇。
- 涌现行为:跪向亡魂而非医师。 角色卡从未定义”跪”这个动作。但当残忍度=0.057,情感控制=0.034时,系统自动产出了跪拜行为 — 并且区分了忏悔的对象是死者,而非听者。
25个心智模型痕迹,无一可由角色卡或世界书直接解释。
刘禅:三重级联与沉默觉醒
角色:刘禅/安乐公,亡国之君,以”扶不起的阿斗”著称。7轮对话设定在洛阳宴会 — 司马昭的忠诚试探场景。此测试专为验证v9优化而设计。
- 三重级联突变(v9共振验证)。 T3中,fool_persona、grief_for_shu、survival_instinct三个通过network_links相互关联的维度同时触发突变。这在之前的测试中从未出现。共振矩阵使得一个维度的应力削弱关联维度的精度,形成正反馈循环,直到整个耦合系统同步崩溃。这正是真实心理崩溃的模式 — 不是单一防线的退让,而是整个防御体系的同步瓦解。
- 沉默变量的觉醒。 royal_dignity(皇室尊严)初始值仅0.15 — 近乎熄灭。7轮中无人直接提及”尊严”或”皇帝”。但每一轮间接刺激(旧臣的泪水、被命令遗忘故国、被当众宣判无能)都在静默积累负荷。T6时,负荷越过阈值,royal_dignity从0.117跳至0.711。理论预测值0.70,观察值0.711 — v9的渐进突变公式精确验证。尊严不需要被提起就会苏醒。恰恰因为它被践踏得太深,它才最终反弹。
- 涌现行为:笑声替代哭泣。 角色卡设定”自成都陷落后再未哭过”。当grief_for_shu达到0.782时,系统找到了替代出口 — 疯狂的笑声成为不可能流出的眼泪。还有”刘禅早就死在那个宴会上了”的自我死亡认知、同一句”此地甚乐”在两个不同信念状态下承载完全相反的情感载荷、以及系统自发创建的新维度survival_vs_legacy。
- 正面事件恢复验证。 T4中贾充的善意安慰后,新负荷积累从0.32-0.34骤降至0.004-0.007,情绪强度从0.98降至0.95。正面经历确实在为受伤的角色提供喘息空间。
20个心智模型痕迹。每一个都是v9引擎在信念网络动态变化、维度间共振传导、渐进式突变计算和正面事件恢复机制共同作用下的涌现产物。
NSP-roleplay 是我从自己制作的NSP-analysis(叙事剧本/小说审计项目)中抽离出来的小项目,它沿用了我迭代和重构数次的心智模型引擎和NSP的核心元语。心智模型引擎覆盖1182个单元测试。架构将计算(Python)与生成(LLM)分离,确保人格演化是确定性的、可复现的、可审计的。关于角色塑造以及心智模型的架构设计,我参考了前人的心理学研究、编剧/电影的实证理论研究、认知论和信息论,以我个人的认知作为佐证和确认,我的结论是:灵魂有如时间,没有实体,人类无法准确丈量它,只能通过对现象的观察和分析,设计更接近准确的模型去观察和计算它。
如果你在构建AI伴侣,想要角色真正成长而不只是表演 — 代码本身就是论证。