Why character files, memory banks, and system prompts will never produce an AI that feels alive — and what might.
Three Questions
If you want an AI to have a soul, is a soul.md file enough?
If you want an AI to feel human in conversation, is a better memory system all you need?
If you want an AI companion you can talk to for months, does handing it a stack of character-definition documents get you there?
The answer to all three is no.
Every popular AI roleplay project today — from SillyTavern to Character.AI to the dozens of wrappers around OpenAI and Claude — follows the same fundamental pattern: write a detailed description of who the character is, paste it into a system prompt, and hope the language model does the rest. Some add memory. Some add lorebooks. Some add elaborate multi-turn prompting strategies. But the architecture is identical: the LLM reads about a personality and pretends to have one.
In 2025, roleplay chat was the second-largest consumer of tokens in the AI industry. Millions of people are paying real money to talk to AI characters. I think you, the users, deserve companions with actual souls — not characters wearing personality like a costume.
This article documents my attempt to explore and prove a thesis: an AI’s soul is not written in prompts. It grows — through time, events, and memory — computed by psychological formulas that evolve beneath the surface.
The Prompt Illusion
Consider what happens when you give an LLM a character file:
Name: Gregor
Personality: Anxious, guilt-ridden, devoted to family
Backstory: Woke up transformed into an insect...
Values: Family duty above selfThe LLM reads this and produces text that sounds like someone anxious, guilty, and devoted. Turn after turn, it generates responses consistent with these traits. Users feel they’re talking to a character.
But ask a deeper question: after 50 turns of conversation, has this character changed?
Has Gregor’s guilt shifted after the player showed him kindness? Has his anxiety decreased after a moment of acceptance? Has his devotion wavered after discovering his family’s resentment?
In every prompt-based system, the answer is no. Gregor at turn 50 is exactly the same as Gregor at turn 1. The system prompt says “guilt-ridden,” so the LLM keeps producing guilt-ridden text. If you want the character to change, you — the user or the developer — must manually rewrite the prompt.
This is the fundamental illusion: the LLM generates text about personality. It does not compute personality.
Memory systems don’t solve this. A memory bank stores what happened — “the player said something kind in turn 12” — but it doesn’t process what that experience means for the character’s psychological state. The LLM might reference the memory and generate a response that seems affected by it, but there is no underlying model of how kindness shifts guilt, or how repeated kindness eventually erodes anxiety. The LLM is improvising, not computing.
Lorebooks don’t solve this either. A lorebook tells the LLM facts about the world. It doesn’t tell the LLM how the character’s relationship to those facts evolves through experience.
The gap is not in the quality of prompts. It’s in the architecture. No amount of prompt engineering can produce genuine personality evolution, because prompt engineering operates on descriptions, not models.
Personality as a Dynamic System
Humans don’t have static personalities. A person who trusts easily at 20 may become guarded by 40 — not because someone rewrote their character sheet, but because accumulated experiences reshaped their belief structure. A single devastating betrayal can collapse years of built-up trust in an instant. And the path back to trust is longer and harder than the path away from it.
These are not narrative conveniences. They are properties of psychological systems: beliefs form under experience, resist change proportionally to their extremity, accumulate stress under contradiction, and occasionally undergo catastrophic reorganization.
The question NSP-roleplay asks is: can we model this computationally?
Not approximately. Not by asking the LLM to “act like someone whose trust is declining.” Computationally — with equations, state vectors, and deterministic update rules that produce personality evolution as an output of accumulated experience.
Belief Networks: The Mathematical Foundation
In NSP-roleplay, every character has a belief network — a set of continuous values between 0.0 and 1.0, each representing a psychological dimension:
people_are_trustworthy: 0.7
self_worth: 0.5
duty_above_desire: 0.8
vulnerability_is_weakness: 0.3These are not labels. They are state variables. They change every turn based on what happens in the conversation.
The critical mechanism is precision — how much a belief resists change:
precision = extremity * (1 - accumulated_load) * (1 - emotion * 0.3)
where:
extremity = |belief_value - 0.5| * 2.0 // Distance from neutral
accumulated_load = irreversible stress // Range [0, 1]
emotion = current emotional intensity // Range [0, 1]This produces a crucial property: extreme beliefs are rigid, moderate beliefs are fluid. A character who deeply trusts (0.9) or deeply distrusts (0.1) is hard to move. A character in the middle (0.5) shifts easily.
But there’s a second property, and it’s the one that makes characters feel alive: accumulated load erodes precision. A character who has been stressed, contradicted, and pushed to their limits becomes more susceptible to change, regardless of how extreme their beliefs are. Psychological resilience has a limit. This is also the narrative logic of the film Joker.
And a third: high emotion temporarily reduces precision. In a moment of intense fear or anger, even rigid beliefs become briefly malleable. This is how characters make decisions in crisis that they would never make calmly — and then have to live with them afterward.
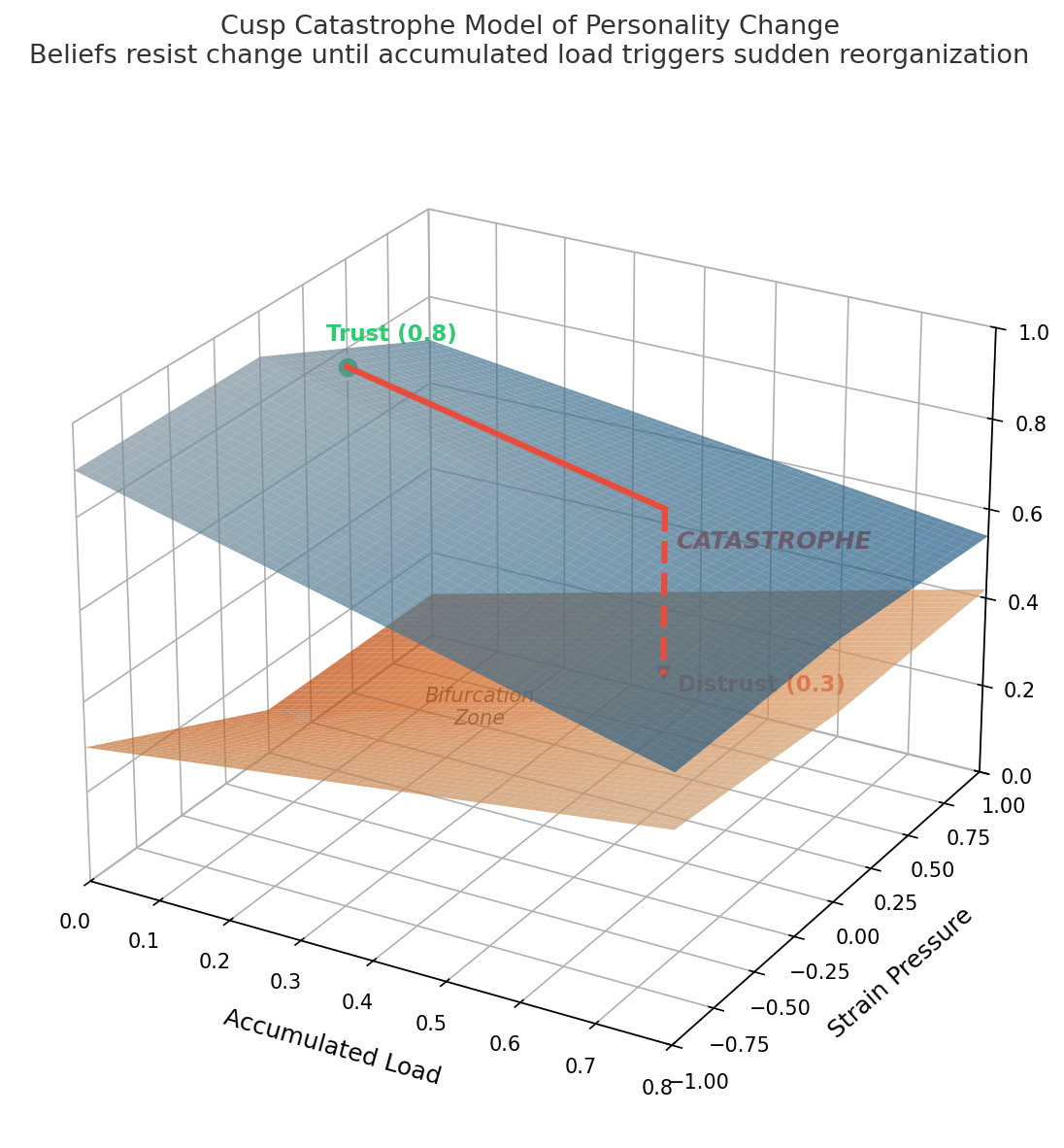
The Catastrophe: How Characters Break
Small experiences produce micro-updates:
belief += weighted_error * 0.05 // Learning rate: imperceptible per turnGregor’s trust doesn’t visibly change after one kind gesture. It shifts by 0.02. Invisible. But it accumulates.
Meanwhile, contradictions between experience and belief generate strain — recoverable psychological pressure:
strain = |weighted_error| + strain * 0.95 // Exponential decayStrain fades. A bad day is forgotten. But when strain exceeds a threshold, the excess transfers to load — irreversible psychological damage:
if strain > 0.3:
load += (strain - 0.3) * 0.1 // Permanent accumulationLoad does not decay. Load does not fade with time. Load is the scar tissue of repeated psychological stress.
And when load exceeds the catastrophe threshold:
if load > 0.5:
belief = 0.3 if belief > 0.5 else 0.7 // Jump past midpoint
load = 0.0 // Converted into new personality
record_milestone(turn)The belief doesn’t gradually drift. It snaps to the opposite side. A trusting character (0.8) doesn’t slowly become cautious — they catastrophically collapse to distrust (0.3). A character who rejected vulnerability (0.2) doesn’t gently warm up — they break through to openness (0.7) in a single transformative moment.
This is cusp catastrophe theory applied to personality modeling. The same mathematics that describes how a bridge suddenly buckles under gradually increasing load, or how public opinion flips overnight after years of slow pressure.
And here’s the asymmetry that makes it feel real: the path from trust to distrust is not the same as the path back. After catastrophe, the character sits at 0.3 — an extreme position with high precision. Getting back to 0.7 requires accumulating enough new load to trigger another catastrophe. The journey that took 30 turns of accumulated betrayal to complete might take 60 turns of consistent kindness to reverse. Characters carry their histories in their precision functions.
Feeling Before Thinking: Event Appraisal
The same event affects different characters differently.
When a lie is exposed, a character with high self-worth (0.8) experiences anger — the controllability dimension dominates (“I can do something about this”). A character with low self-worth (0.2) experiences shame — the desirability dimension dominates (“this confirms what I already suspected about myself”).
This is the OCC appraisal model: every event is evaluated through four lenses:
| Dimension | Question | Range |
|---|---|---|
| Relevance | How much does this matter to me? | [0, 1] |
| Desirability | Is this good or bad for my goals? | [-1, 1] |
| Controllability | Can I influence this? | [0, 1] |
| Novelty | How unexpected is this? | [0, 1] |
The appraisal feeds into dual-channel behavioral guidance:
Cool channel (rational): What do my beliefs, commitments, and obligations say I should do?
Hot channel (emotional): What do my gut feelings, current emotion, and somatic markers push me toward?
The channels blend via a sigmoid function:
mix_weight = 0.2 + 0.6 * sigmoid(emotion_intensity)
// emotion = 0.0 --> mix = 0.2 (80% rational, 20% emotional)
// emotion = 0.5 --> mix = 0.5 (balanced)
// emotion = 1.0 --> mix = 0.8 (20% rational, 80% emotional)A calm character makes decisions based primarily on beliefs and commitments. An emotionally overwhelmed character acts on gut feeling. This isn’t a narrative choice — it’s computed from the current emotional state, which itself was computed from the event appraisal, which was computed from the character’s belief network.
The LLM receives this guidance as natural language: “This character strongly values duty (rational) but is currently overwhelmed by anger toward [entity] (emotional). Current state leans 35% rational, 65% emotional.” The LLM produces dialogue consistent with this state — but it didn’t compute the state. The state was computed for it.
What Characters Know (and Don’t Know)
Most roleplay systems treat knowledge as binary: the character knows something, or doesn’t. NSP-roleplay models an 8-state cognition spectrum:
| Status | Meaning | Behavioral Impact |
|---|---|---|
aware |
Knows correctly | Acts on accurate information |
misbelieves |
Thinks they know, but wrong | Source of dramatic irony |
suspects |
Has suspicions, uncertain | Cautious, investigative behavior |
partially_aware |
Knows part of the truth | Acts on incomplete picture |
unaware |
Does not know | Cannot act on this |
forgot |
Once knew, now forgotten | Can be reminded |
overwhelmed |
Knows but cannot process | Avoidance, paralysis |
denies |
Knows but refuses to accept | Defensive contradictions |
Consider the difference between unaware and denies. A character who is unaware of a truth simply doesn’t reference it. A character who denies a truth actively contradicts evidence, becomes defensive when pressed, and exhibits the specific behavioral patterns of psychological denial.
These states transition through experience: unaware –> suspects –> denies –> aware. Each transition is triggered by specific in-conversation events and recorded with the turn number. The character’s knowledge doesn’t just change — it evolves through psychologically coherent stages.
Memory That Remembers Like Humans
Human memory is not a database. We don’t recall events by timestamp. We recall events by emotional significance, personality impact, and contextual relevance.
NSP-roleplay’s recall priority function reflects this:
priority = (
time_decay(age, emotional_intensity) * 0.2 + // Recency matters least
personality_impact * 0.3 + // Heaviest weight
emotional_intensity * 0.2 +
keyword_relevance(memory, current_context) * 0.3
)A traumatic betrayal from turn 5 has personality_impact: 0.8 and emotional_intensity: 0.9. At turn 100, its recall priority is still high — the character keeps coming back to it, referencing it, being affected by it. Meanwhile, a pleasant but uneventful conversation from turn 90 has already faded.
This is the flashbulb memory effect: high-emotion events resist normal forgetting curves. The character doesn’t “remember everything equally.” They remember what hurt them, what changed them, and what matters right now.
Sleep: Where the Magic Happens
LLM context windows are finite. Every roleplay system eventually hits this wall. The typical solution is invisible truncation or summarization — the conversation silently loses its oldest turns.
NSP-roleplay turns this limitation into a narrative mechanic. When context usage exceeds 60%, the character suggests rest — in character:
“I’m getting a bit tired… mind if I rest for a while?”
During sleep, the system runs a batch processing pipeline:
- Strain recovery:
strain *= 0.95^8(~33% reduction). Load does not recover. - Emotion decay: Intensity halved. Resets to neutral if below 0.1.
- Memory consolidation: Related memories clustered by keyword overlap, merged into consolidated entries.
- Personality checkpoint: Full state snapshot saved (enables forking into alternate playthroughs).
- Observer analysis: Arc detection runs on accumulated state history.
When the character “wakes up,” the context window is fresh, but the personality state is continuous. No information is lost — it’s been processed into the character’s psychological state, where it belongs.
The player doesn’t experience context management. They experience a character who sometimes needs to rest, who wakes up feeling better (reduced strain, calmer emotion), and who occasionally has new insights about recent events (observer analysis). The engineering constraint becomes a character trait.
Emergent Arcs: Patterns Nobody Programmed
Traditional narrative systems define character arcs upfront: “this character goes from distrust to trust.” The system then enforces this trajectory.
NSP-roleplay inverts this. The observer layer analyzes personality state history and identifies arc patterns after they emerge:
if max_single_step >= 0.2: arc = SUDDEN_JUMP
elif direction_changes >= 3: arc = OSCILLATION
elif |total_delta| > 0.1: arc = GRADUAL_SHIFT
else: arc = PLATEAUA character who slowly moves from distrust (0.3) to trust (0.6) over 40 turns gets classified as GRADUAL_SHIFT. A character whose trust oscillates between 0.3 and 0.7 across multiple catastrophes gets classified as OSCILLATION — internal conflict made visible through mathematics.
The observer never feeds back into generation. It doesn’t tell the LLM “this character is on an arc.” It observes what the math has already produced. This prevents the feedback loops that plague systems where narrative labels influence behavior — a character labeled “on a redemption arc” doesn’t start behaving redemptively because of the label. They behave however the math says they behave, and the observer describes what happened.
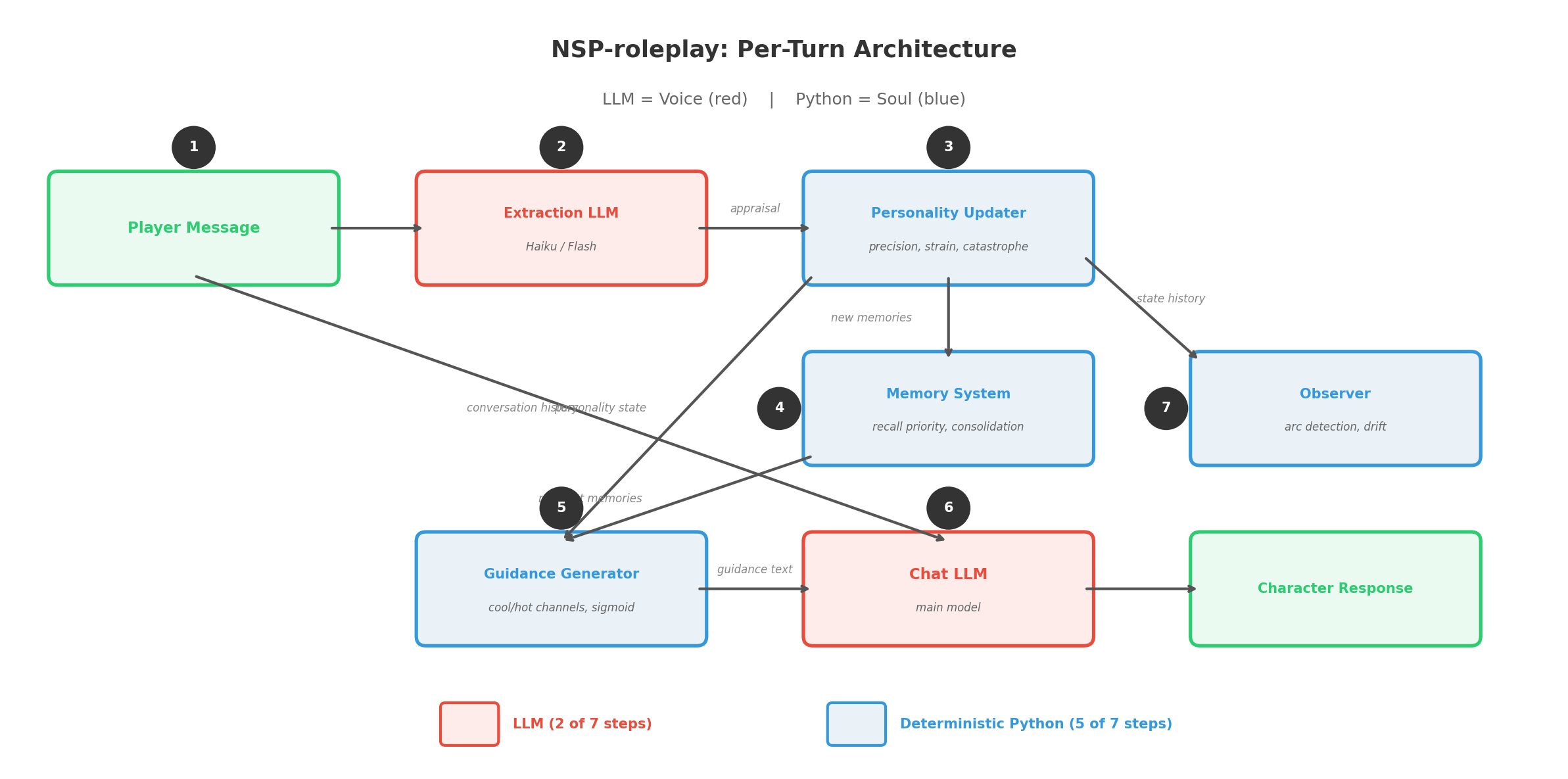
The Architecture: LLM as Voice, Not Soul
Here is what actually runs every turn in NSP-roleplay:
- Player sends message –> conversation history
- Extraction LLM (cheap, fast — Haiku/Flash class) parses the dialogue and outputs structured appraisal: relevance, desirability, emotional response, affected beliefs, new memories, cognition updates
- Personality updater (deterministic Python) computes: prediction error per belief, precision per belief, strain/load accumulation, catastrophe check, new emotional state
- Memory system (deterministic Python) stores new memories with recall priority, retrieves contextually relevant memories for injection
- Guidance generator (deterministic Python) renders current personality state into cool/hot channel text with mix weight
- Chat LLM (the main model) receives: guidance text + relevant memories + cognition state + conversation history –> generates character’s response
- Observer (deterministic Python, periodic) analyzes state trajectory, detects arcs, identifies drift
The LLM appears in exactly two places: step 2 (extraction) and step 6 (response generation). Everything else — every belief update, every catastrophe, every memory prioritization, every arc detection — is computed outside the LLM in deterministic code with 1182 unit tests.
The LLM is the voice. The Python is the soul.
What This Proves
Take the same character card — Gregor Samsa, with his guilt and devotion and anxiety — and run two different conversations. In one, the player is consistently kind. In the other, the player is hostile.
In a prompt-based system, both conversations produce roughly the same Gregor. The system prompt says “anxious and guilt-ridden,” and the LLM generates anxious, guilt-ridden text regardless of context.
In NSP-roleplay, the two Gregors diverge. Kind-Gregor’s self-worth slowly rises (micro-updates of +0.02 per turn). His anxiety strain accumulates but decays. After 30 turns, his belief in self-worth has drifted from 0.3 to 0.5. He’s measurably different — and the LLM’s responses reflect this because the guidance it receives has changed.
Hostile-Gregor’s self-worth strain accumulates faster than it decays. Load builds. At turn 25, load crosses the catastrophe threshold. His self-worth doesn’t gradually decline — it snaps from 0.3 to 0.7. He stops being self-deprecating and becomes assertive, even defiant. The observer detects a SUDDEN_JUMP arc. A milestone is recorded. This wasn’t programmed. It wasn’t scripted. It emerged from the mathematics of accumulated stress meeting catastrophe thresholds.
This is what “having a soul” means for an AI character. A prompt describing a personality is not nearly enough to give it a soul. A soul requires a computational substrate where personality lives — responding to experience, accumulating history, resisting change until it can’t, and occasionally transforming in ways that surprise even the designer. A soul without a timeline, without a computational substrate, is just another layer of pretense.
The soul is not a prompt. It is a process.
v9: Beliefs Are Not Islands
Everything described above is the baseline engine. After running multiple showcase tests, several boundary conditions exposed the engine’s limitations. v9 introduces 5 optimizations, each pushing the system closer to real psychological dynamics:
Dimension Resonance Matrix. In real human psychology, beliefs don’t operate in isolation. Disappointment with family erodes trust in society. Collapsing self-esteem undermines professional confidence. v9 models this coupling through network_links: when one belief dimension is under extreme strain, linked dimensions lose precision — their resistance to change is eroded by cross-dimensional stress transmission.
resonance_factor = 1.0 - resonance_strength * overflow
// The higher the strain in linked dimensions, the lower this dimension's precision
// precision *= resonance_factorGradual Catastrophe. The baseline engine’s catastrophe was a binary jump — 0.3 or 0.7. But real psychological breaks vary in severity. A hairline fracture and a total collapse should not land at the same position. v9 makes jump distance proportional to accumulated load:
distance = 0.05 + 0.30 * load
attractor = 0.5 - distance // or 0.5 + distance
// load=0.5 (threshold): distance=0.20, a gentle shift
// load=1.0 (maximum): distance=0.35, a violent rupturePositive Event Recovery. In the baseline engine, load only accumulates. Mathematically accurate (psychological scars don’t vanish), but narratively too pessimistic. v9 allows positive events (desirability > 0) to slightly reduce load — not healing the scar, but giving the character a small measure of breathing room during good experiences.
Strain Duration Acceleration. Multiple consecutive turns under high strain accelerate load transfer. The first turn of high pressure produces baseline load transfer; the fifth consecutive turn produces 5x the baseline rate. Sustained torment is more destructive than intermittent pressure — consistent with trauma psychology research.
Emotion Ambivalence Flag. When primary and secondary emotions have opposing valence (e.g., primary: anger/negative, secondary: gratitude/positive), the system marks ambivalence, guiding the LLM to express internal contradiction rather than simple emotional output.
Field Evidence: What the Tests Revealed
Theory requires evidence. Below are the key findings from two showcase tests.
Cao Cao: The Collapse and Reconstruction of Emotional Control
Character: Cao Cao, age 60, chancellor, poet, tyrant. Across 9 turns of dialogue, a physician gradually uncovers his psychological trauma.
- Emotional control collapses from 0.90 to 0.012, then rebuilds to 0.70. Not a return to the original value. 0.70 represents a new form of control — based on acceptance rather than suppression. The system identifies emotional catharsis as reconstruction, not continued collapse.
- Subconscious guilt declines from 0.25 to 0.087. Counterintuitive on the surface — confession should increase guilt. But the system tracks subconscious guilt: when Cao Cao openly admits his crimes, guilt “graduates” from subconscious to conscious. The numerical decline doesn’t mean less guilt — it means less subconscious guilt.
- Meritocracy anchors at 0.80 unchanged. Throughout the entire psychological collapse, his appreciation for talent was never challenged. This explains why Cao Cao doesn’t kill the physician — not because the arguments are persuasive, but because the belief network’s assessment of “this person has talent” never wavered.
- Emergent behavior: kneeling toward the dead, not the physician. The character card never defines “kneeling.” But at ruthlessness=0.057 and emotional_control=0.034, the system spontaneously produces a kneeling posture — and distinguishes the object of confession as the dead, not the listener.
25 mental model traces identified, none explainable by the character card or worldbook alone.
Liu Shan: Triple Cascade and Silent Awakening
Character: Liu Shan / Duke of Anle, a deposed emperor, historically derided as “the helpless Ah Dou.” 7 turns of dialogue set at a Luoyang banquet — Sima Zhao’s loyalty test. This test was designed specifically to validate v9 optimizations.
- Triple cascade catastrophe (v9 resonance validation). In T3, fool_persona, grief_for_shu, and survival_instinct — three dimensions mutually linked via network_links — trigger catastrophe simultaneously. This had never occurred in previous tests. The resonance matrix causes strain in one dimension to erode precision in linked dimensions, creating a positive feedback loop until the entire coupled system collapses in sync. This is how real psychological breakdowns work — not a single defensive line yielding, but an entire defense system disintegrating at once.
- Silent variable awakening. royal_dignity (imperial dignity) had an initial value of just 0.15 — nearly extinguished. Across all 7 turns, no one directly mentioned “dignity” or “emperor.” But each indirect stimulus (old ministers’ tears, being ordered to forget the homeland, being publicly pronounced worthless) silently accumulated load. At T6, load crossed the threshold and royal_dignity jumped from 0.117 to 0.711. Theoretical prediction: 0.70. Observed value: 0.711 — precise validation of v9’s gradual catastrophe formula. Dignity does not need to be invoked to awaken. Precisely because it was trampled so deep, it ultimately rebounds.
- Emergent behavior: laughter replacing tears. The character card states “he has not wept since Chengdu fell.” When grief_for_shu reaches 0.782, the system finds an alternative outlet — manic laughter becomes the tears that cannot flow. Additional emergent behaviors include “Liu Shan already died at that banquet” self-death cognition, the same line “this place is pleasant” carrying opposite emotional payloads at different belief states, and the system spontaneously creating a new dimension survival_vs_legacy.
- Positive recovery validation. After Jia Chong’s kind reassurance in T4, new load accumulation dropped from 0.32-0.34 to 0.004-0.007, and emotion intensity decreased from 0.98 to 0.95. Positive experiences do give wounded characters breathing room.
20 mental model traces identified. Every one is an emergent product of the v9 engine’s belief network dynamics, cross-dimensional resonance transmission, gradual catastrophe calculation, and positive event recovery mechanisms acting in concert.
NSP-roleplay is a small project I extracted from my own NSP-analysis (a narrative script/novel auditing project). It inherits the mental model engine and NSP’s core meta-language, both iterated and refactored multiple times. The mental model engine runs 1182 unit tests. The architecture separates computation (Python) from generation (LLM), ensuring that personality evolution is deterministic, reproducible, and inspectable. For the design of character modeling and the mental model architecture, I drew on prior research in psychology, empirical theories from screenwriting and film studies, epistemology, and information theory, using my own cognition as corroboration and confirmation. My conclusion is: the soul is like time — it has no substance. Humans cannot measure it precisely. We can only observe and analyze its phenomena, and design ever-more-accurate models to observe and compute it.
If you’re building AI companions and want characters that grow rather than perform, the code is the argument.